
🔎 Introduction
The rise of Large Language Models (LLMs) such as GPT-4, LLaMA, and Claude has revolutionized how we generate text, analyze data, and automate complex tasks. However, this progress comes with a pressing concern: how can we train and evaluate these models without compromising user privacy?
Real-world data — especially in sensitive domains like healthcare, finance, and government — is heavily regulated by laws such as GDPR, LGPD, and HIPAA. This creates barriers to innovation and collaboration. The proposed solution: synthetic data.
But key questions remain:
- What exactly is synthetic data?
- How is it generated?
- Can it truly protect privacy?
- What are its risks and limitations?
In this article, we’ll explore these questions with clear explanations, practical Python code, and real-world use cases.
🧩 What is Synthetic Data?
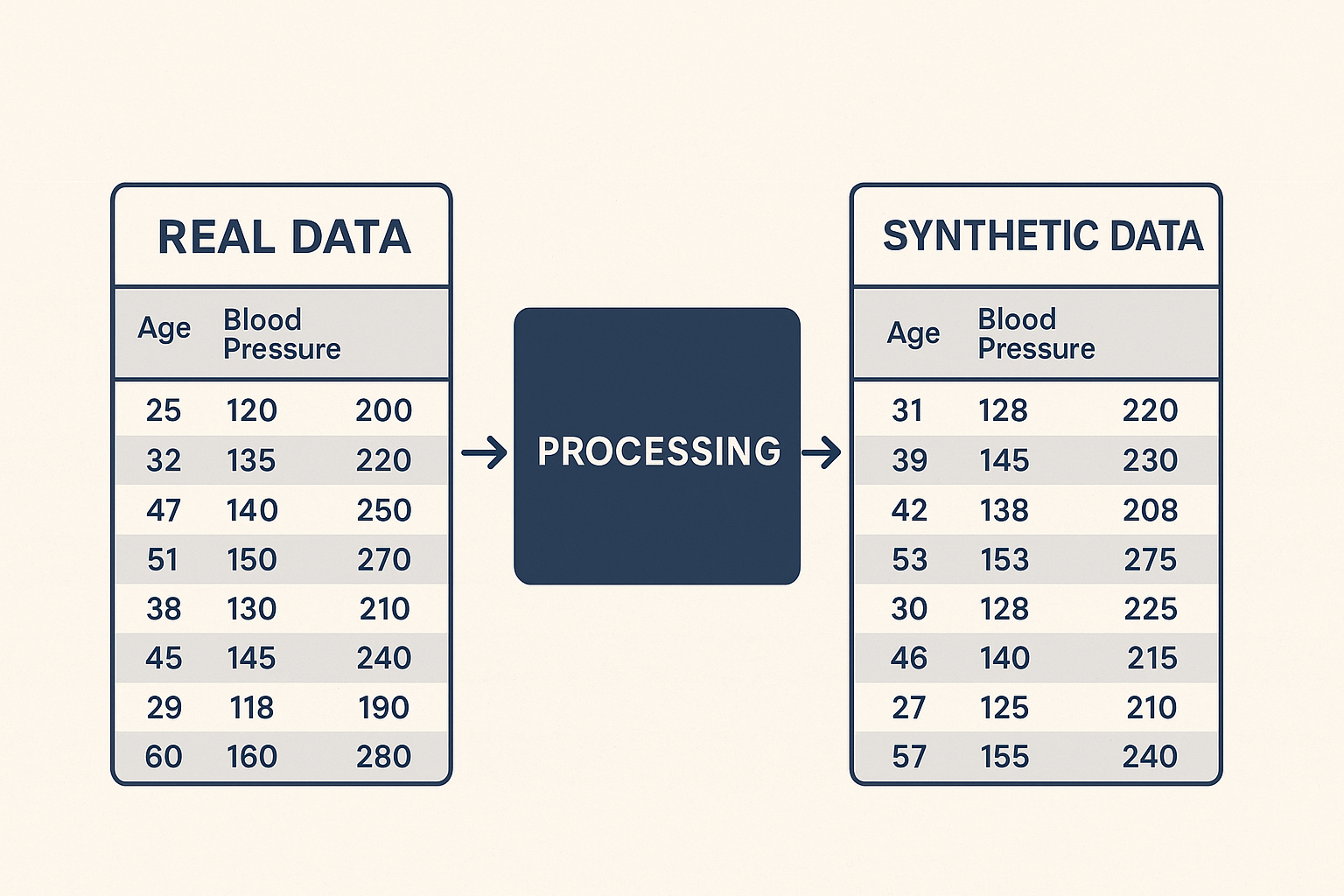
Synthetic data is artificially generated information that mimics the statistical properties of real data.
For example: imagine a hospital with a dataset of 1 million medical records. Sharing this data is legally impossible. However, a model can learn its patterns and generate new fictitious records that preserve the same distributions without exposing actual patients.
Difference from other privacy-preserving methods
- Anonymization → removes identifiers but can be re-identified through data linkage.
- Pseudonymization → replaces identifiers with codes, but the original data still exists.
- Synthetic data → creates new records that do not correspond to real individuals.
⚙️ How Synthetic Data is Generated
Several approaches exist, ranging from simple rule-based methods to advanced deep learning techniques:
1. Rule-based simulations
- Analysts define distributions (e.g., ages between 20–80, glucose between 70–200).
- Useful for testing, but fails to capture complex real-world patterns.
2. Statistical models
- Use probabilistic distributions to model continuous and categorical variables.
- Handle simple dependencies but struggle with nonlinear relationships.
3. Deep learning models
- GANs (Generative Adversarial Networks): generator and discriminator compete until realistic samples emerge.
- VAEs (Variational Autoencoders): compress data into latent space and generate new samples.
- LLMs: generate synthetic text, from dialogues to full Q&A datasets.
📐 Evaluating Quality and Privacy
Generating synthetic data is not enough. We must evaluate whether it is useful and safe.
Main evaluation criteria
- Statistical Fidelity
- Synthetic data must preserve correlations, distributions, and patterns.
- Example: if real diabetic patients have an average age of 55, synthetic patients should reflect this.
- Practical Utility
- Machine Learning models trained on synthetic data should perform similarly to those trained on real data.
- Privacy
- Synthetic data must not allow re-identification of real individuals.
- Tools like differential privacy and inference attack simulations help measure risk.
🐍 Python Example
Here’s a simple Python example using the SDV (Synthetic Data Vault) library:
import pandas as pd
from sdv.tabular import CTGAN
# Example real dataset
real_data = pd.DataFrame({
"age": [25, 32, 47, 51, 38, 45, 29, 60, 41, 35],
"blood_pressure": [120, 135, 140, 150, 130, 145, 118, 160, 138, 128],
"cholesterol": [200, 220, 250, 270, 210, 240, 190, 280, 230, 215]
})
# Training the model
model = CTGAN()
model.fit(real_data)
# Generating synthetic samples
synthetic_data = model.sample(5)
print(synthetic_data)
✅ This produces synthetic patient-like records that preserve relationships between variables without exposing real individuals.
⚠️ Limitations and Risks
Synthetic data is powerful, but it’s not a silver bullet. Several risks and challenges remain:
1. Overfitting and Memorization
Generative models like GANs and LLMs can memorize training examples and accidentally reproduce them.
➡️ Example: generating a synthetic medical record that is almost identical to a real patient’s file, breaking privacy guarantees.
2. Bias Reproduction and Amplification
If the original dataset contains biases — such as underrepresentation of certain demographics — synthetic data will replicate and possibly amplify these biases.
➡️ This is especially dangerous in healthcare, hiring, or credit scoring systems.
3. Relative Privacy
Synthetic data is not absolute privacy. Attackers can attempt re-identification by correlating synthetic patterns with public datasets.
4. Questionable Data Utility
Synthetic data may “look realistic” but lack subtle dependencies between variables, making it less useful for downstream ML tasks.
5. Complex Validation
Balancing fidelity, utility, and privacy is challenging. Stronger privacy guarantees may reduce realism and weaken model performance.
📌 Real-World Use Cases
1. Healthcare
Hospitals and labs use synthetic patient data for research, teaching, and algorithm testing — without exposing real patient records.
➡️ Example: generating synthetic diabetic patient records for training predictive models.
2. Finance
Banks can generate synthetic transaction data for fraud detection and credit risk analysis.
➡️ Example: millions of realistic-but-fake financial transactions to train anomaly detection systems.
3. E-commerce and Marketing
Retailers simulate customer behavior with synthetic profiles to test recommendation systems and marketing campaigns.
➡️ Example: simulating Black Friday shopping behaviors.
4. Government and Public Sector
Governments can publish open synthetic datasets that mimic real censuses or surveys while protecting citizens’ privacy.
➡️ Example: a synthetic census dataset for policy research.
5. LLM Training and Evaluation
Synthetic data benefits LLMs in two major ways:
- Data augmentation for niche domains (e.g., synthetic medical Q&A pairs for healthcare chatbots).
- Evaluation with synthetic benchmarks instead of private datasets.
🔮 Future Trends
- Regulation: the EU and other jurisdictions are moving toward synthetic data standards.
- Multimodality: combining text, images, and tabular data into synthetic datasets.
- LLM-powered evaluation: using AI itself to assess the quality of generated data.
- Federated learning integration: combining synthetic data and distributed training for highly restricted environments.
🚀 Conclusion
Synthetic data is becoming a strategic pillar of AI development. It enables:
- Privacy-preserving innovation.
- Safer experimentation in sensitive industries.
- Expanded training data for LLMs.
But it’s not risk-free. Issues like bias amplification, memorization, and validation complexity mean synthetic data must be used carefully and evaluated rigorously.
📚 References
- Xu, L. et al. (2019). Modeling Tabular Data Using Conditional GAN.
- Stadler, T. et al. (2023). Synthetic Data: Current Approaches, Challenges, and Opportunities.
- Scisimple – Using Synthetic Data for Text Classification
- DataCamp – LLM Evaluation
- Toolify – Advanced LLM Evaluation
Deixe um comentário